Introduction
When I was working on Tarwiiga AdGen at Tarwiiga, I needed to finetune an LLM for Google ads generation, but the data was not found, so I needed to create it from scratch, the tool was taking input from two words or three and give a JSON output, so we need a dataset that contains different inputs with JSON output, but there was a problem getting the input, I tried to make the LLM suggest inputs but it was containing lots of duplicates, so I decided to scrape online data to be an input, I was first using regular programming to scrape data but then improved it to use AI then found another killer way that helped me scrape millions of data points at no time, here is I am talking about those three levels of scraping data for anyone who may be interested.

Basic Level: Scrape with regular programming
At the basic level, I was using regular Python scripts with Selenium and Beautifulsoup, where Selenium simulates user behavior on the browser and Beautifulsoup with Requests for scrapping HTML and extracting texts, this was working for basic stuff where the data is public or the data is in the first page without needing you to scrape endless feeds, but when it needs login and scrapping endless feed this was like a hell and I couldn’t manage to fix all of the bugs!
Advanced Level: Scrapping with AI
At the advanced level, while this couldn’t solve the problem of the basic level, but incorporated a new way of scrapping, instead of relying on manually writing Python code that scrapes HTML and extracts data in JSON, I shifted this task to LLM to do it, just giving it the HTML and tell it to extract the content you want and put them in JSON, looping through list of HTML documents will give you a list of JSON objects that you could save it in CSV file or database, but this also rise a new problem of limited token length of LLM and sometimes LLM won’t give accurate results.
Pro Level: Scrapping with the request URL
At the pro level, you don’t need to do the above stuff, you could just take the request URL especially if it is an endless feed to get the JSON response, this needs you to open the inspector of the browser and go to the network tab and refresh the page then scroll and track changes until you find the request URL that fetches data, and take this URL and just make a request to it to give you the response in JSON, this way was very powerful for me as I managed to scrape millions of data at no time, also I didn’t face any problems related to handling endless feed or handling login or not even needed to depend on AI and its context length limit.
Here is a detailed guide on how to get data from the Twitter (X) feed using the request UR.
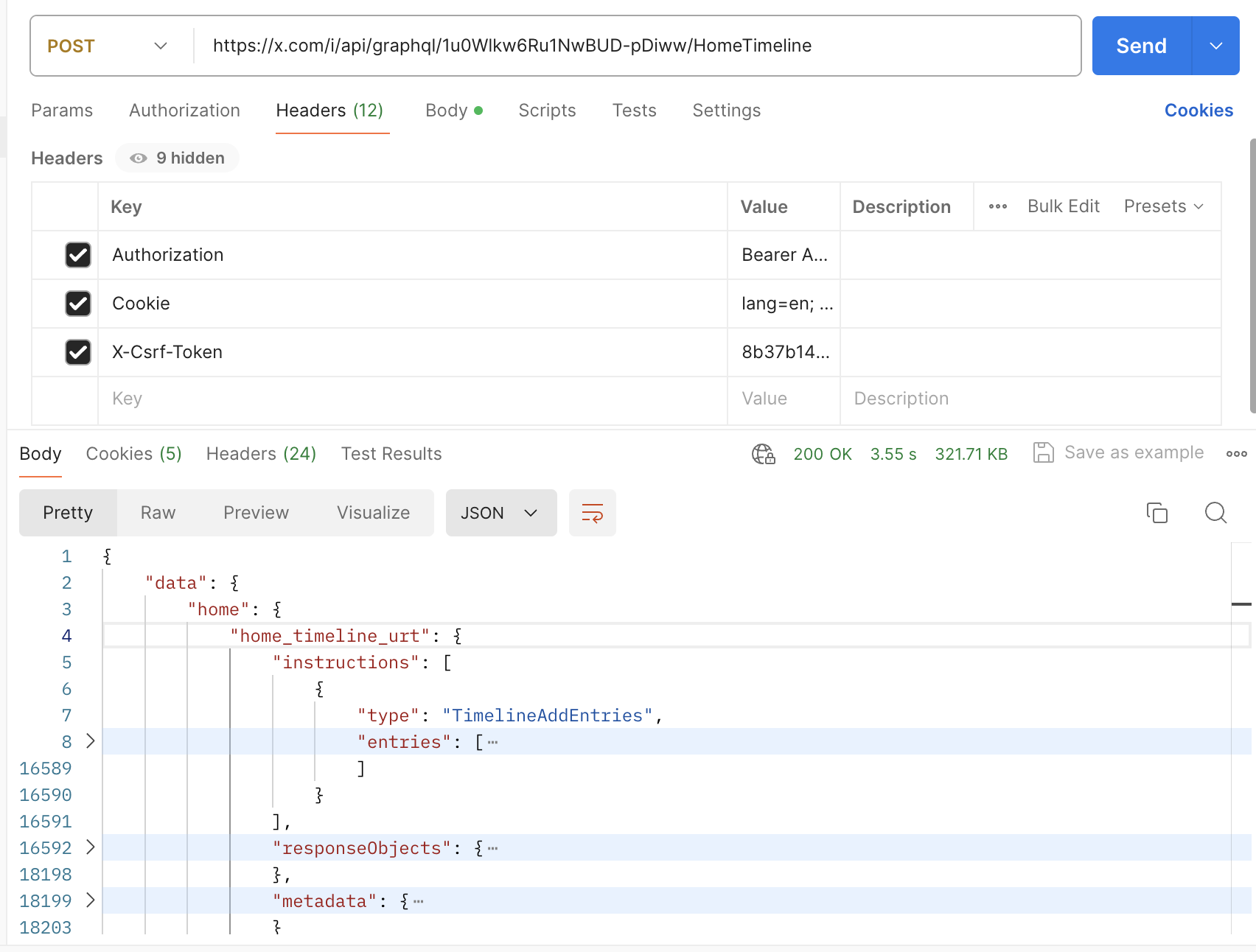
First, open https://x.com and then inspect and go to the network tab, refresh, and start scrolling until you find this HomeTimeline click on it and it will give you all the details of the request and response.
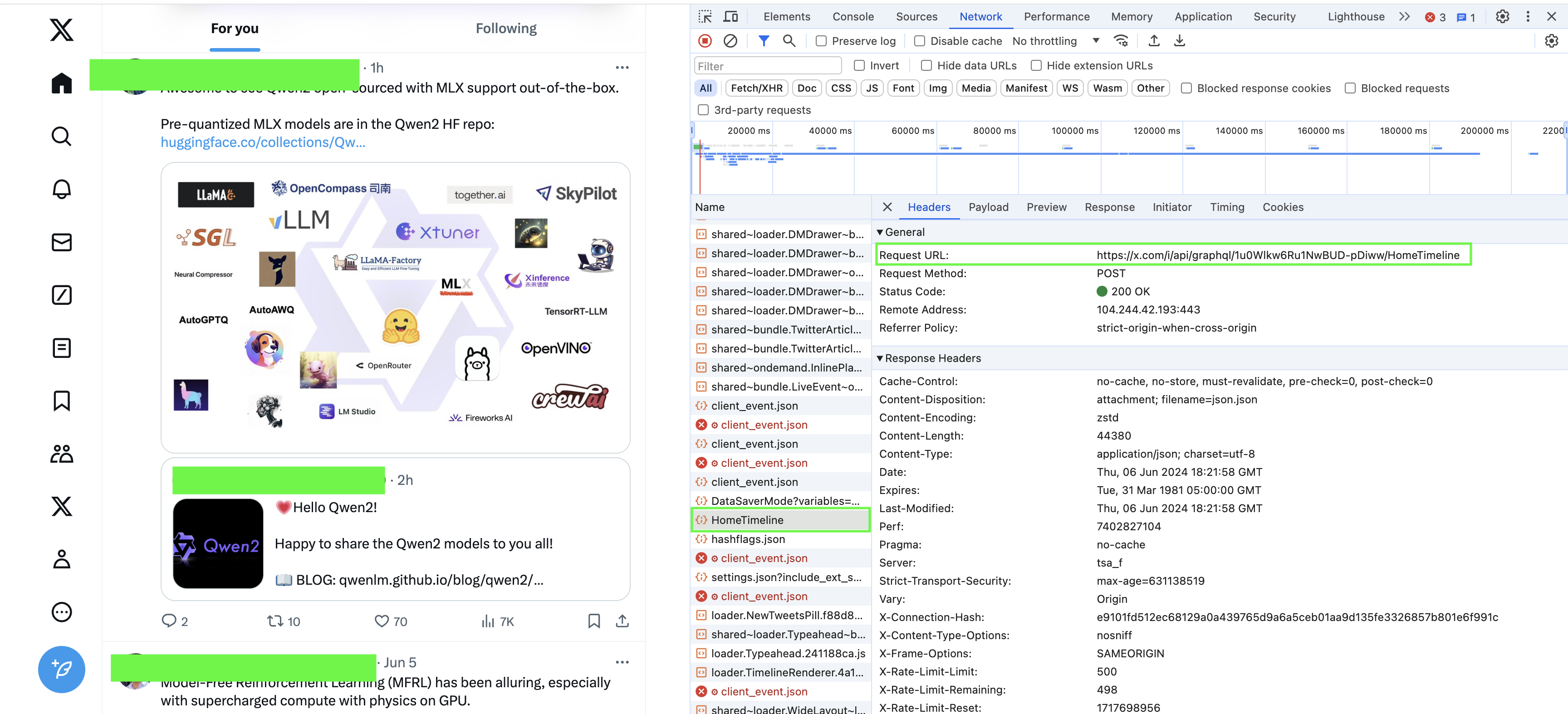
Then go to preview to see a preview of the response
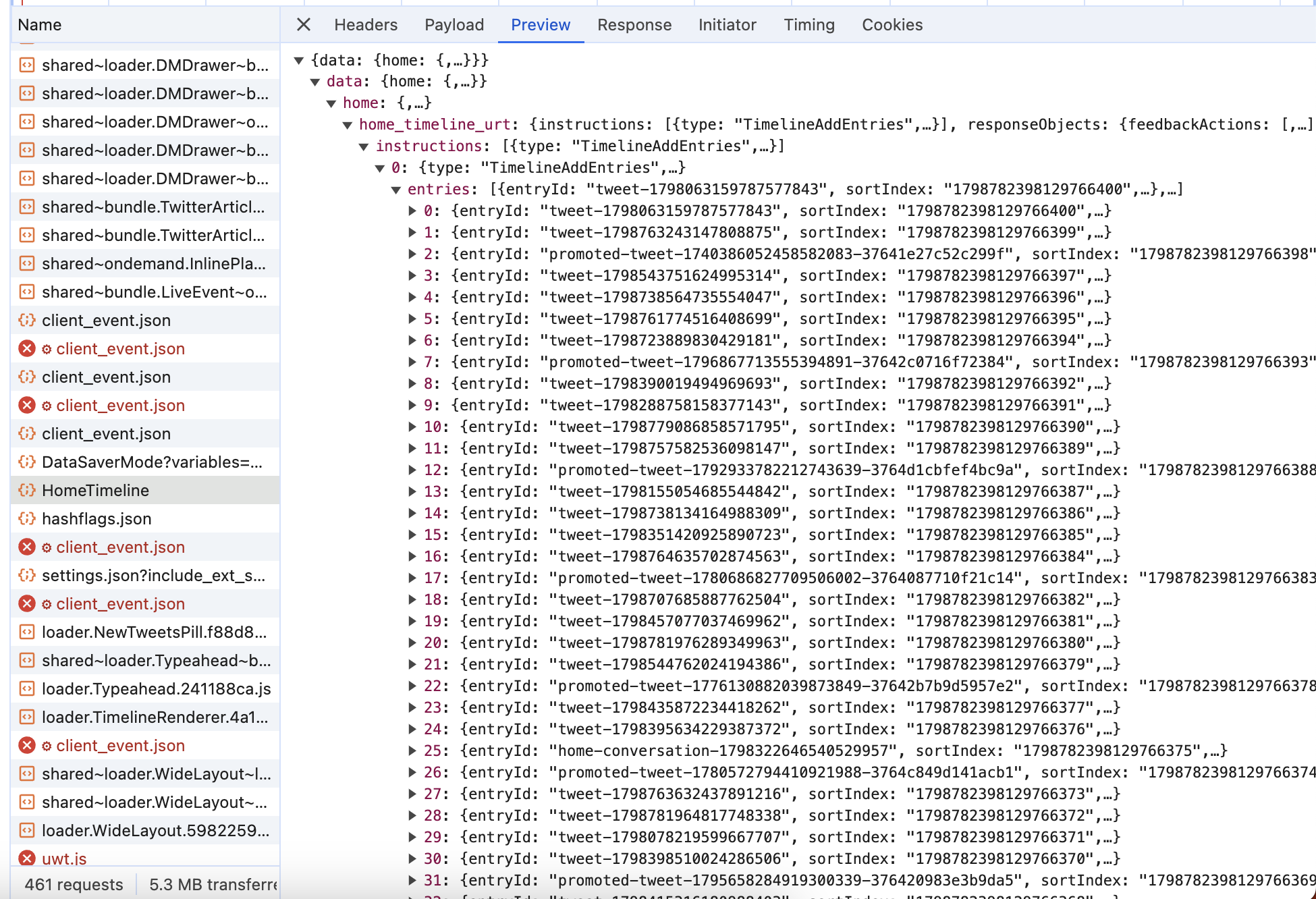
And here is the payload
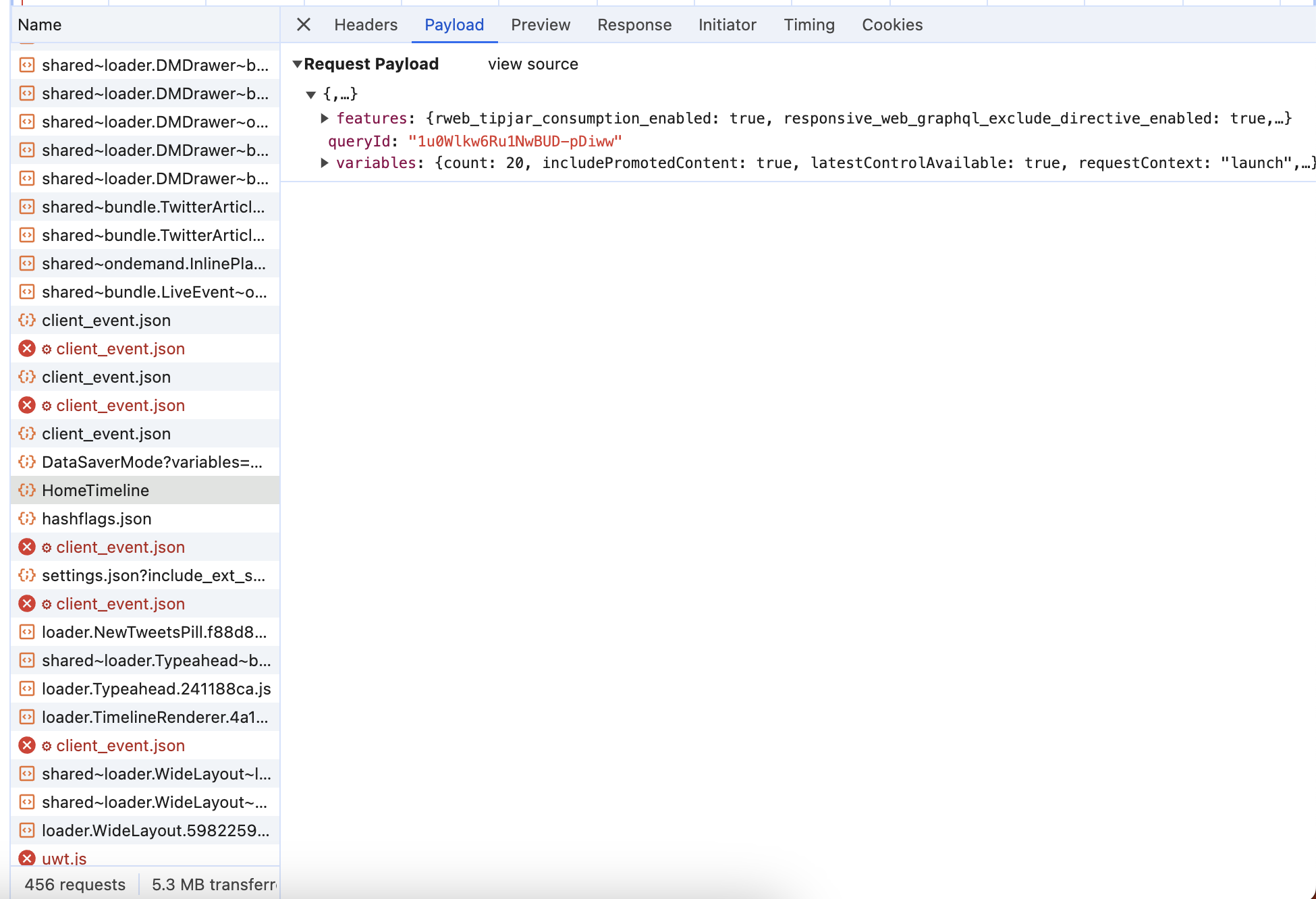
Take the request URL and the payload and put them in Postman
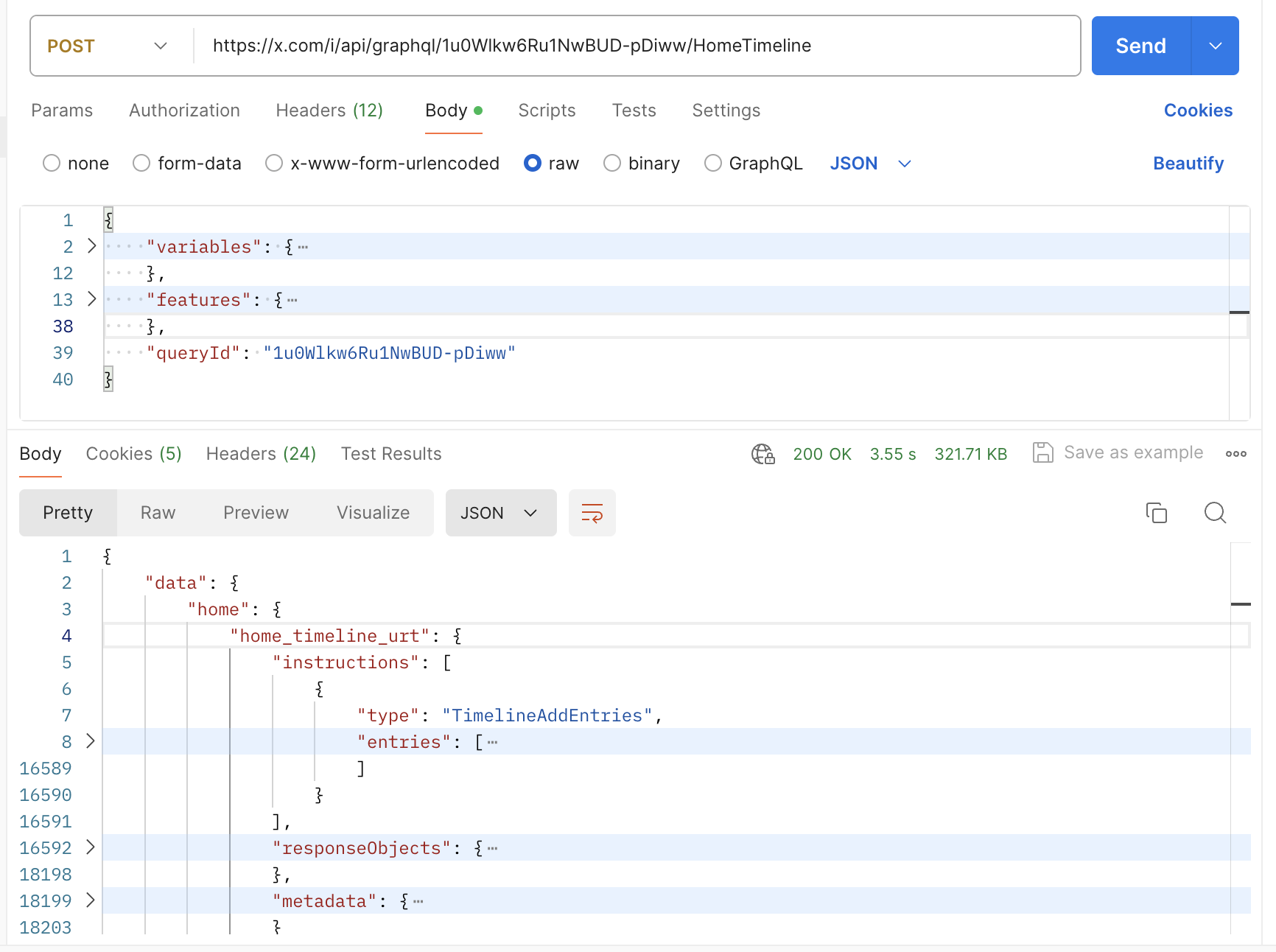
Put any headers that come with the request and then click send and you will get the response
You could click on the code icon at Postman to get the code that does this request in your language. Here is the code in Python.
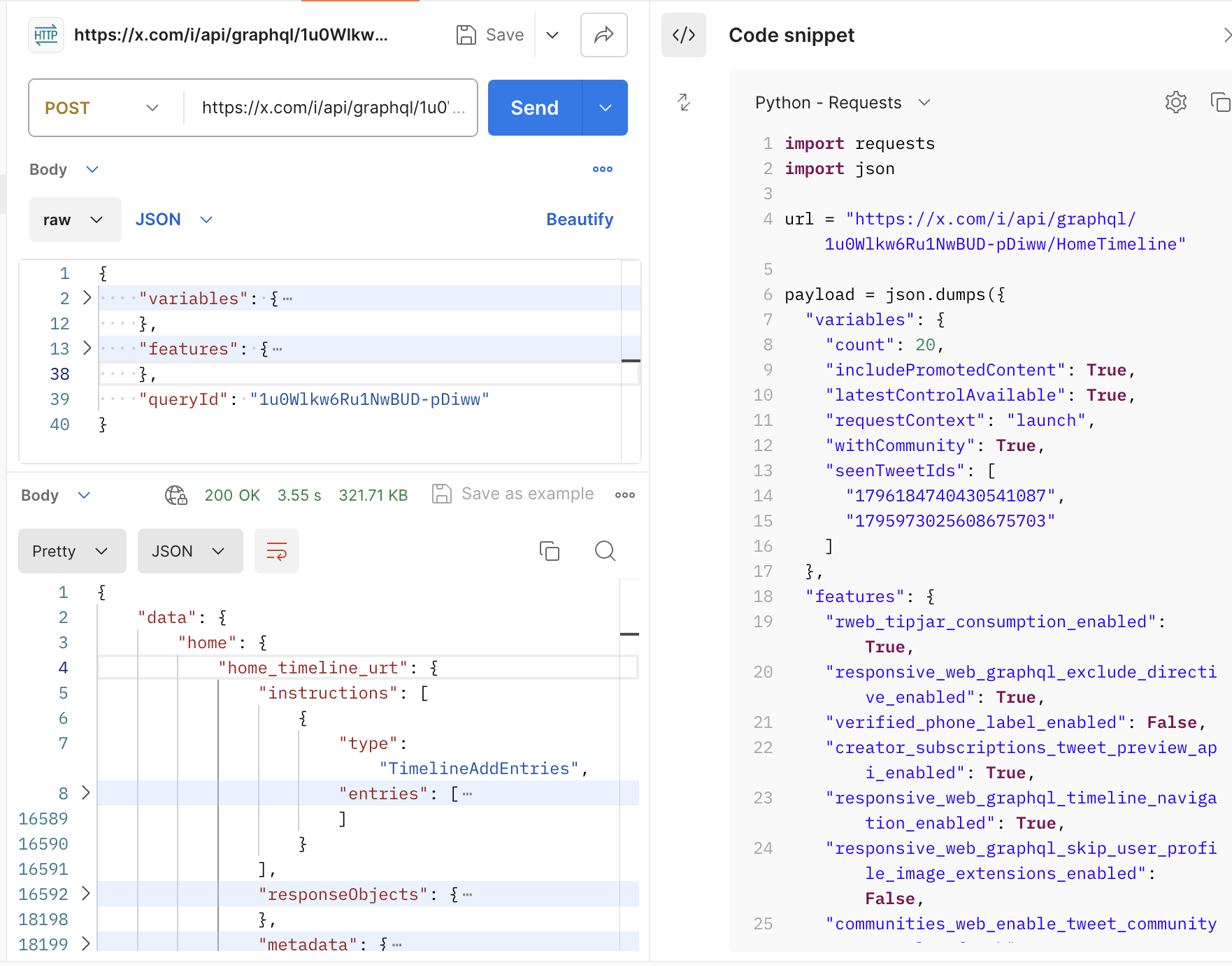
And that is it! In this way, you could get millions of data points as I did on other specific websites for our use cases.
Conclusion
I hope this article was helpful to you, please don’t hesitate to ask me any questions and you can reach me on Twitter (X) and Linkedin